Swift de Cero a Experto #2: Colecciones — Array, Set y Dictionary bajo el capó
Descubre cómo funcionan las colecciones de Swift por dentro: cuándo usar cada una, su complejidad algorítmica, y la elegancia del copy-on-write.
En el artículo anterior exploramos los tipos de datos fundamentales — todos value types que viven cómodamente en el stack. Hoy la historia cambia. Las colecciones de Swift (Array, Set, Dictionary) son structs — value types en papel — pero su contenido real vive en el heap.
¿Cómo resuelve Swift esta contradicción? Con una de las optimizaciones más elegantes del lenguaje: copy-on-write. Y entenderla te va a cambiar la forma de pensar sobre el rendimiento de tu código.
Las colecciones de Swift son un acto de magia: se comportan como valores, pero por dentro son tan eficientes como las referencias.

Las tres colecciones fundamentales
Swift ofrece tres tipos de colección para cubrir prácticamente cualquier necesidad de almacenamiento de datos. Cada una tiene su personalidad, sus fortalezas y su complejidad algorítmica. La documentación oficial las presenta en Collection Types:
- Array — Colección ordenada de valores. Permite duplicados.
- Set — Colección no ordenada de valores únicos.
- Dictionary — Colección no ordenada de pares clave-valor.
Las tres comparten algo en común: son generic types — genérico significa que el mismo código funciona para cualquier tipo de elemento (Array<String>, Array<Int>, etc.) sin reescribirlo. Cuando escribes [String], en realidad estás escribiendo Array<String>. El compilador genera código especializado para cada tipo concreto — y eso tiene implicaciones de rendimiento que veremos más adelante. (Cubrimos generics en profundidad en el artículo #12.)
Array: la colección que más vas a usar
Un Array almacena valores del mismo tipo en una lista ordenada. El mismo valor puede aparecer múltiples veces en posiciones diferentes.
Creación
// Array vacíovar numbers: [Int] = []var anotherEmpty = [Int]()
// Con valores inicialesvar fruits = ["🍎", "🍊", "🍋"]
// Con valor por defectovar zeros = Array(repeating: 0, count: 5)// [0, 0, 0, 0, 0]
// Combinando arrayslet moreFruits = fruits + ["🍇", "🍓"]// ["🍎", "🍊", "🍋", "🍇", "🍓"]Nota cómo en var fruits = ["🍎", "🍊", "🍋"] no necesitas escribir el tipo — el compilador infiere [String] automáticamente. Esto es type inference en acción, sin costo en runtime.
Acceso y modificación
var shoppingList = ["Eggs", "Milk", "Flour"]
// Leerlet first = shoppingList[0] // "Eggs"shoppingList.count // 3shoppingList.isEmpty // false
// AgregarshoppingList.append("Butter") // al finalshoppingList.insert("Salt", at: 0) // en posición específicashoppingList += ["Sugar", "Vanilla"] // concatenar
// ModificarshoppingList[0] = "Sea salt" // reemplazar unoshoppingList[2...4] = ["Bread", "Cheese"] // reemplazar rango
// Eliminarlet removed = shoppingList.remove(at: 0) // retorna el elementolet last = shoppingList.removeLast() // evita consultar countIteración
// Simplefor fruit in fruits { print(fruit)}
// Con índicefor (index, fruit) in fruits.enumerated() { print("\(index): \(fruit)")}Rendimiento
Aquí es donde un buen desarrollador se diferencia de uno excelente. No basta con saber qué hace cada operación — necesitas saber cuánto cuesta:
Nota rápida sobre la notación: O(1) significa que el costo se mantiene constante sin importar cuántos elementos haya; O(n) significa que el costo crece en proporción al número de elementos n.
- Acceso por índice
array[i]→ O(1) — instantáneo append(_:)→ O(1) amortizado — casi siempre instantáneoinsert(_:at:)al inicio → O(n) — debe mover todos los elementosremove(at:)al inicio → O(n) — debe mover todos los elementoscontains(_:)→ O(n) — recorre elemento por elementocount→ O(1) — almacenado como propiedad
¿Por qué append es O(1) amortizado? Porque Array pre-aloca espacio extra en el heap. Cuando el buffer se llena, Swift crea uno nuevo con el doble de capacidad y copia todo. Eso pasa raramente, así que en promedio cada append es O(1).
var numbers = [Int]()print(numbers.capacity) // 0
numbers.append(1)print(numbers.capacity) // crece (el valor exacto depende de la implementación)
numbers.append(2)numbers.append(3)print(numbers.capacity) // crece exponencialmente — podrías ver números distintosLos valores exactos de capacity son un detalle de implementación de la librería estándar y del toolchain, no una garantía — lo que sí se promete es que la capacity crece de forma exponencial, que es lo que hace que append sea O(1) amortizado.
Set: cuando el orden no importa pero la unicidad sí
Un Set almacena valores únicos del mismo tipo sin orden definido. Es tu mejor opción cuando necesitas verificar si un elemento existe — y necesitas que sea rápido.
Requisito: Hashable
Para almacenar un tipo en un Set, ese tipo debe conformar el protocolo Hashable. Todos los tipos básicos de Swift (String, Int, Double, Bool) ya son Hashable. Si creas tus propios tipos, puedes hacerlos Hashable — hablaremos de protocolos en el artículo #13.
Creación
// Set vacíovar letters = Set<Character>()
// Con array literal (necesita type annotation)var genres: Set<String> = ["Rock", "Jazz", "Hip hop"]
// Forma corta — elige una de las dos (Set se debe declarar, el tipo se infiere)var shortFormGenres: Set = ["Rock", "Jazz", "Hip hop"]Nota que un Set no tiene syntactic sugar como [Element] para Array. Siempre necesitas escribir Set<Element> o al menos Set.
Acceso y modificación
var genres: Set = ["Rock", "Jazz", "Hip hop"]
genres.count // 3genres.isEmpty // false
genres.insert("Electronic") // agrega
if let removed = genres.remove("Rock") { print("\(removed) removed")}
genres.contains("Jazz") // true — ¡O(1)!remove retorna un Optional — una caja que o contiene un valor o es nil. if let removed = ... lo desempaqueta solo cuando hay un valor. Cobertura completa en el artículo #11.
Operaciones de conjuntos
Esta es la verdadera potencia de Set — operaciones matemáticas de conjuntos en una línea:
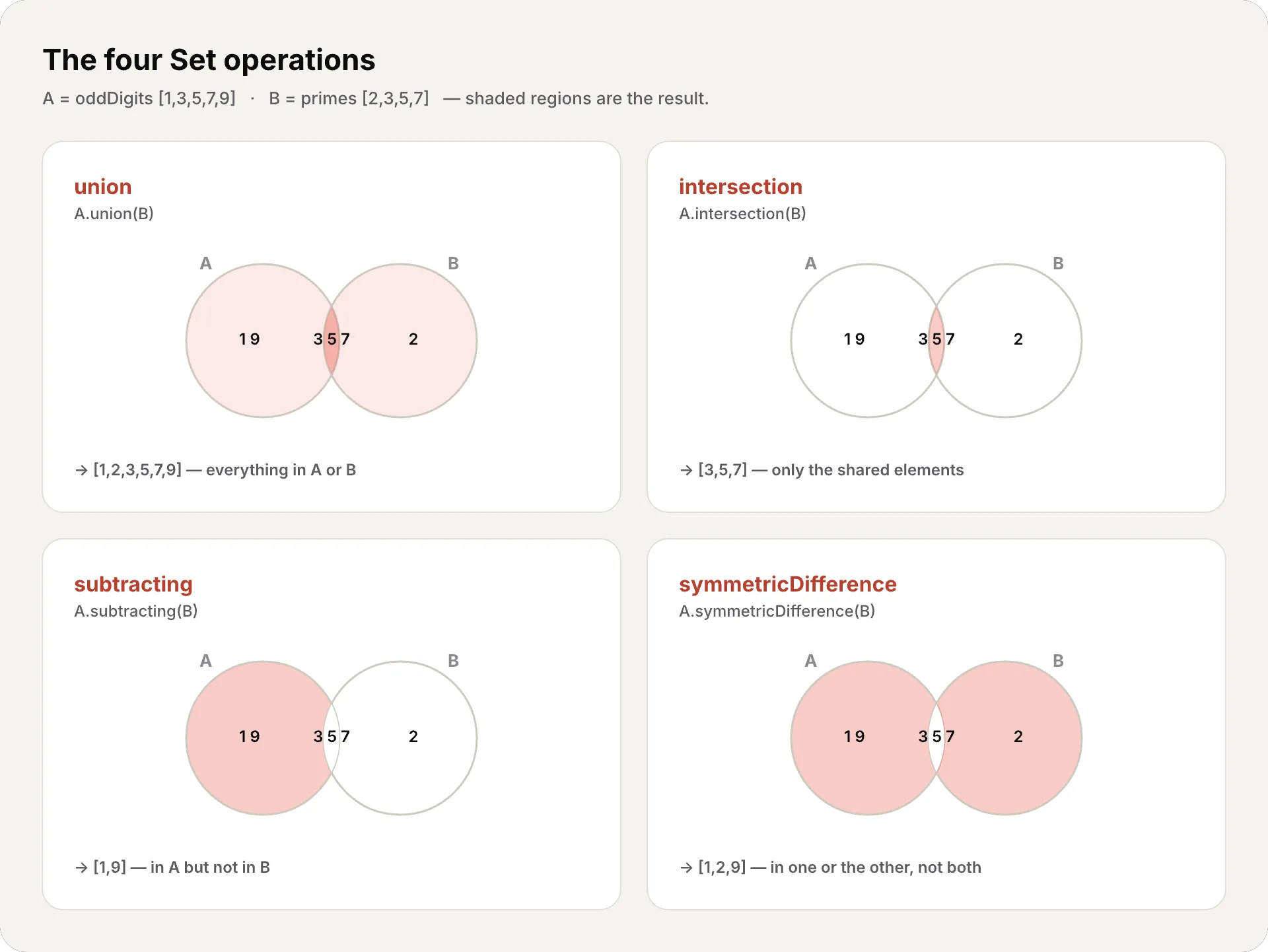
let oddDigits: Set = [1, 3, 5, 7, 9]let evenDigits: Set = [0, 2, 4, 6, 8]let primes: Set = [2, 3, 5, 7]
// Unión — todos los elementos de ambosoddDigits.union(evenDigits).sorted()// [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
// Intersección — solo los comunesoddDigits.intersection(primes).sorted()// [3, 5, 7]
// Diferencia — los que están en A pero no en BoddDigits.subtracting(primes).sorted()// [1, 9]
// Diferencia simétrica — los que están en uno u otro, pero no ambosoddDigits.symmetricDifference(primes).sorted()// [1, 2, 9]Relaciones entre sets
let pets: Set = ["🐶", "🐱"]let farm: Set = ["🐮", "🐔", "🐑", "🐶", "🐱"]let city: Set = ["🐦", "🐭"]
pets.isSubset(of: farm) // truefarm.isSuperset(of: pets) // truefarm.isDisjoint(with: city) // true — nada en comúnRendimiento
insert(_:)→ O(1) — usa hash tableremove(_:)→ O(1) — usa hash tablecontains(_:)→ O(1) — ¡esta es la razón de usar Set!union,intersection, etc. → O(n) — proporcional al tamaño
contains en O(1) es la diferencia clave. Si tienes 1 millón de elementos y necesitas verificar si uno existe, un Array necesita revisar hasta 1 millón de elementos. Un Set lo hace en tiempo constante gracias a su hash table: pasa el valor por una función hash para calcular un número que apunta casi directamente a su casilla, así encuentra el elemento sin recorrer toda la colección.
Dictionary: pares clave-valor
Un Dictionary almacena asociaciones entre claves del mismo tipo y valores del mismo tipo, sin orden definido. Es como un diccionario real: buscas por la palabra (clave) y obtienes la definición (valor).
Creación
// Vacíovar namesOfIntegers: [Int: String] = [:]
// Con literal (tipo inferido como [String: String])var airports = ["MEX": "Mexico City", "GDL": "Guadalajara"]La clave debe conformar Hashable — igual que en Set.
Acceso y modificación
var airports = ["MEX": "Mexico City", "GDL": "Guadalajara"]
airports.count // 2airports.isEmpty // false
// Agregar o actualizarairports["MTY"] = "Monterrey"
// updateValue retorna el valor anterior (si existía)if let oldValue = airports.updateValue("CDMX Benito Juárez", forKey: "MEX") { print("Was: \(oldValue)")}
// Leer — siempre retorna Optionalif let name = airports["MEX"] { print(name) // "CDMX Benito Juárez"}
// Eliminarairports["GDL"] = nil // forma cortaairports.removeValue(forKey: "MTY") // retorna el valor eliminadoIteración
// Pares clave-valorfor (code, name) in airports { print("\(code): \(name)")}
// Solo clavesfor code in airports.keys { print(code)}
// Solo valoresfor name in airports.values { print(name)}
// Convertir claves/valores a Arraylet codes = [String](airports.keys)let names = [String](airports.values)Rendimiento
- Acceso por clave
dict[key]→ O(1) — usa hash table updateValue(_:forKey:)→ O(1)- Asignar
dict[key] = value→ O(1) removeValue(forKey:)→ O(1)count→ O(1)
Dictionary usa el mismo mecanismo de hash table que Set. Todo acceso por clave es O(1).
¿Cuál colección usar?

La decisión es más simple de lo que parece:
// ¿Necesitas orden y acceso por posición?// → Arraylet history = ["login", "dashboard", "profile"]
// ¿Necesitas unicidad y búsqueda rápida?// → Setlet tags: Set = ["swift", "ios", "mobile"]
// ¿Necesitas buscar por clave?// → Dictionarylet config = ["theme": "dark", "language": "es"]- Array → orden importa, duplicados permitidos, acceso por índice
- Set → orden no importa, sin duplicados, búsqueda O(1)
- Dictionary → asociación clave→valor, búsqueda por clave O(1)
Copy-on-Write: la magia bajo el capó
Llegamos a la parte más importante de este artículo — y la que conecta las colecciones con nuestro hilo de memoria.
Las tres colecciones de Swift son structs — value types. Eso significa que, en teoría, cada vez que asignas un array a otra variable, deberías obtener una copia completa. Con un array de 10,000 elementos, eso sería copiar 10,000 elementos cada vez.
Pero Swift no hace eso. Es mucho más inteligente.
Copy-on-Write es la razón por la que Swift puede darte la seguridad de los value types con el rendimiento de los reference types. Lo mejor de ambos mundos.
¿Cómo funciona?
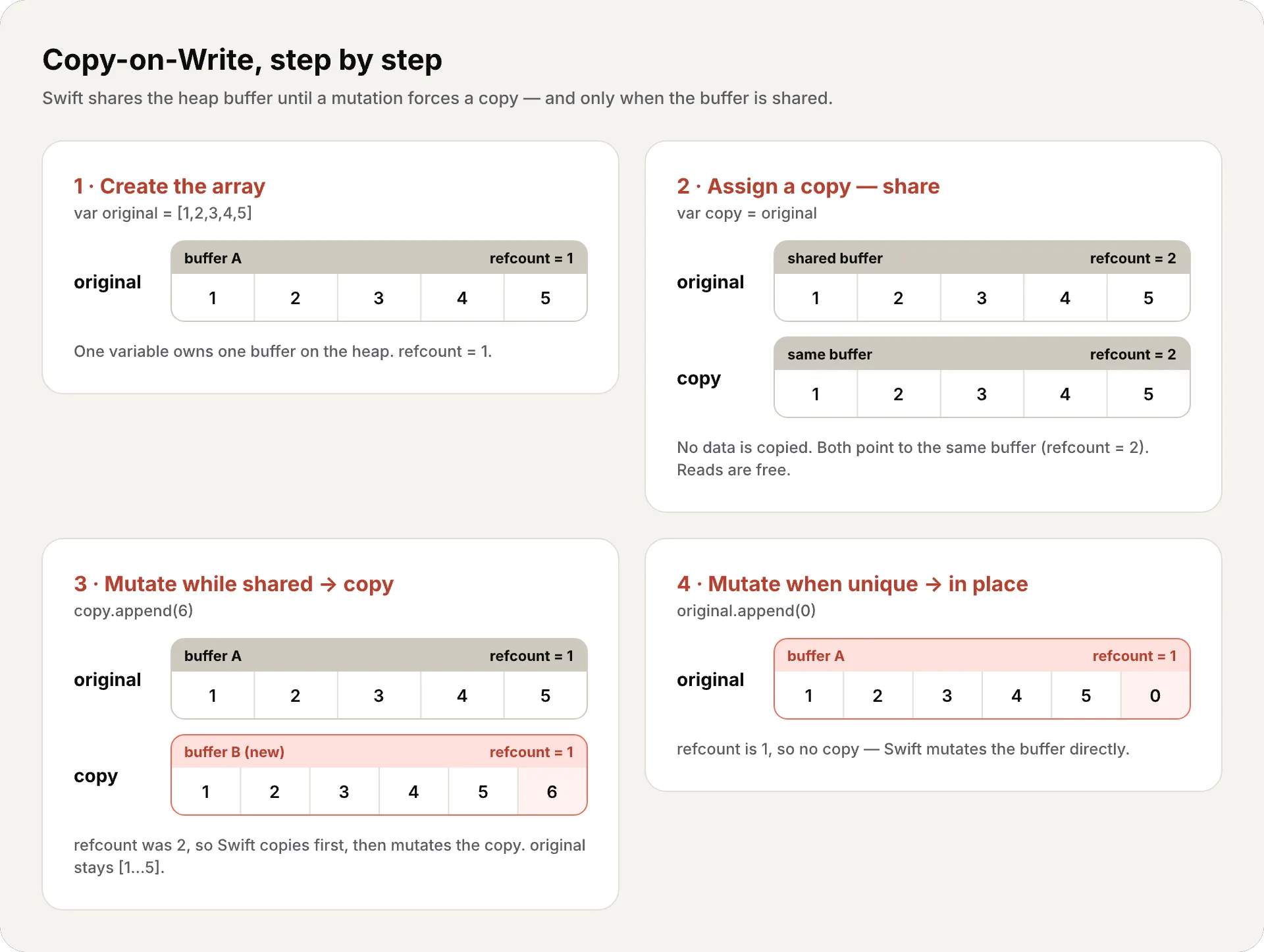
La idea es brillante en su simplicidad:
- Cuando asignas un array a otra variable, Swift no copia los elementos. Ambas variables apuntan al mismo buffer en el heap. Solo incrementa un contador de referencias — simplemente un número que lleva la cuenta de cuántas variables apuntan actualmente al mismo buffer. Cuando es mayor que 1, más de una variable comparte el buffer, así que cualquier mutación debe copiar primero. (Cubriremos este mecanismo de conteo — ARC — en profundidad en el #18.)
- Cuando mutas una de las variables, Swift revisa el contador: ¿hay más de una referencia al buffer?
- Sí → Crea una copia del buffer, modifica la copia. Ahora cada variable tiene su propio buffer.
- No → Modifica directamente. No hay nadie más usando este buffer.
Síguelo paso a paso:
¿Por qué esto importa?
Piensa en este código:
func procesarDatos(_ datos: [Int]) -> [Int] { // datos es una "copia" — pero no se copió nada aún return datos.filter { $0 > 0 } // filter crea un nuevo array, pero datos nunca se copió}
let original = Array(1...10_000)let resultado = procesarDatos(original)// original se pasó "por valor" pero con cero costo de copiaAquí filter conserva solo los elementos que cumplen una condición, y { $0 > 0 } es un closure — una mini-función en línea donde $0 es cada elemento. (Cubrimos closures en detalle en el artículo #6.)
Sin CoW, pasar un array de 10,000 elementos a una función copiaría 80,000 bytes (10,000 × 8 bytes por Int). Con CoW, solo se copia un puntero — 8 bytes. La copia real solo ocurre si la función modifica el array.
La estructura interna
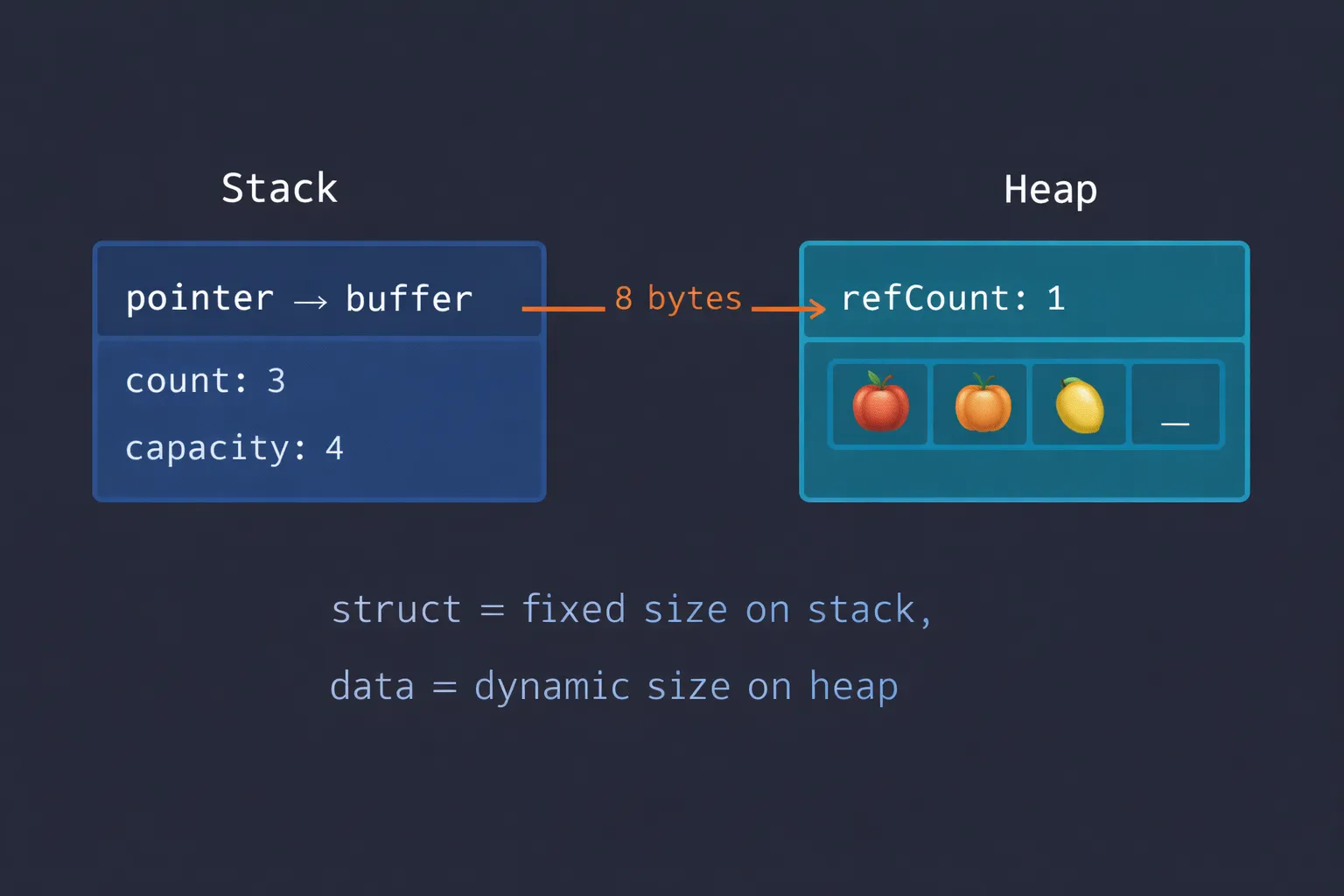
Cada colección de Swift tiene esta estructura en memoria:
┌─────────────────────────────┐│ Stack ││ ┌───────────────────────┐ ││ │ var fruits │ ││ │ → puntero al buffer │ │──────┐│ └───────────────────────┘ │ │└─────────────────────────────┘ │ │┌─────────────────────────────┐ ││ Heap │ ││ ┌───────────────────────┐ │ ││ │ Buffer │◄─┼──────┘│ │ refCount: 1 │ ││ │ count: 3 │ ││ │ capacity: 4 │ ││ │ [🍎] [🍊] [🍋] [_] │ ││ └───────────────────────┘ │└─────────────────────────────┘El struct en el stack es diminuto — en realidad solo un puntero al buffer en el heap (de hecho MemoryLayout<[Int]>.size es 8). El count y la capacity viven en el header del buffer en el heap, junto al refCount que Swift usa para decidir si necesita copiar.
Colecciones y el compilador
Hay algo que mencionamos al principio y vale la pena profundizar: las colecciones de Swift son generic types. Array<Int> y Array<String> son tipos diferentes, y el compilador genera código especializado para cada uno.
Esto se llama generic specialization, y es una de las razones por las que Swift es más rápido que lenguajes con generics basados en type erasure (la información del tipo genérico se descarta en runtime, como Java). Cuando el compilador ve Array<Int>, genera código que trabaja directamente con enteros de 64 bits — sin boxing (envolver valores en objetos del heap), sin indirección, sin overhead.
// El compilador genera código especializado para cada tipolet enteros: [Int] = [1, 2, 3] // Trabaja con Int directamentelet textos: [String] = ["a", "b"] // Trabaja con String directamente// No hay "Object[]" genérico como en JavaRecapitulación
Hoy cubrimos las tres colecciones fundamentales de Swift:
- Array — ordenado, duplicados permitidos, acceso O(1) por índice, append O(1) amortizado
- Set — no ordenado, valores únicos,
containsen O(1) gracias a hash tables, operaciones de conjuntos - Dictionary — no ordenado, pares clave-valor, acceso O(1) por clave
- Copy-on-Write — las colecciones comparten su buffer en el heap hasta que alguien muta, solo entonces se copia
- Generic specialization — el compilador genera código optimizado para cada tipo concreto
Las colecciones de Swift demuestran algo fundamental sobre el lenguaje: no tienes que elegir entre seguridad y rendimiento. Copy-on-Write te da value semantics con reference-type performance.
Lo que viene
En el próximo artículo nos sumergimos en Strings y Characters. Si piensas que un String es “solo texto”, prepárate para descubrir por qué Swift decidió que string[0] no debería existir, qué son los grapheme clusters, cómo Substring comparte memoria con el String original, y la small string optimization que evita ir al heap para textos cortos.
Nos vemos la próxima semana.
Elegir la colección correcta no es un detalle menor — es la diferencia entre una app que vuela y una que se arrastra. Y ahora sabes por qué.
Relacionados
-
- swift
- swift-cero-experto
- swift-fundamentals
Swift de Cero a Experto #8: Structs vs Classes — la decisión que define tu app
Value semantics vs reference semantics, static vs dynamic dispatch, y por qué Apple recomienda structs por defecto. El artículo que cambia cómo piensas en Swift.
-
- swift
- swift-cero-experto
- swift-fundamentals
Swift de Cero a Experto #7: Enumeraciones — más que una lista de casos
Raw values, associated values, enums recursivos con indirect, y cómo el compilador elige la representación mínima en memoria.
-
- swift
- swift-cero-experto
- swift-fundamentals
Swift de Cero a Experto #6: Closures — capturas, memoria y poder funcional
Closure expressions, captura de valores, capture lists, @escaping vs non-escaping y por qué los closures son reference types que viven en el heap.