Dominando Instruments (Parte 3): método científico, Time Profiler avanzado y profiling a escala
Aprende a diagnosticar problemas de rendimiento como un proceso científico. Domina Weight vs Self-Weight, Charge/Prune/Flatten, y escala tu profiling con xctrace.
En la Parte 1 aprendimos a usar Instruments como técnicos — botones, plantillas, filtros. En la Parte 2 nos convertimos en médicos — estudiamos la anatomía de la memoria y los binarios. En la Parte 2.5 vimos esa anatomía en acción — malloc reservando bloques, ARC contando referencias, retain cycles atrapando memoria.
Hoy nos toca el papel más exigente: el patólogo. El patólogo no adivina. Observa la evidencia, forma una hipótesis, diseña un experimento, y deja que los datos confirmen o refuten su teoría. Eso es exactamente lo que vamos a hacer con el rendimiento de nuestras apps.
Un buen diagnóstico no empieza con la herramienta. Empieza con la pregunta correcta.
El método científico del debugging de rendimiento
Imagina un doctor que, sin examinar al paciente, le dice: “Probablemente es el corazón. Vamos a operar.” Suena absurdo, ¿verdad? Pero en desarrollo de software lo hacemos constantemente. “La app está lenta — seguro es el JSON.” “El scroll se traba — debe ser la descarga de imágenes.” Y perdemos horas optimizando la parte equivocada del código.
La alternativa es tratar el debugging de rendimiento como lo que es: un proceso científico.
Los 5 pasos
-
Observar — Describe el síntoma con precisión. No “la app está lenta”. Mejor: “el scroll cae por debajo de 30fps después de cargar más de 500 celdas en el
PersonTableViewController”. -
Formular una hipótesis — Con base en tu conocimiento del código, propón una causa específica y testeable. Ejemplo: “Sospecho que
PeopleStore.peopleestá decodificando el JSON en cada acceso a una celda.” -
Diseñar el experimento — Elige el instrumento adecuado. Si sospechas de CPU, usa Time Profiler. Si sospechas de memoria, Allocations. Define qué vas a medir y en qué condiciones.
-
Medir — Ejecuta el perfil. Resiste la tentación de mirar el código fuente antes de ver los datos. Deja que Instruments hable primero.
-
Interpretar e iterar — ¿Los datos confirman tu hipótesis? Genial, ahora tienes una dirección clara. ¿La refutan? Mejor aún — acabas de ahorrarte horas de trabajo inútil. Formula una nueva hipótesis y repite.
- Fecha / Build / Dispositivo: iPhone 15 Pro, iOS 18.2, build #47, Release
- Síntoma observado: Scroll cae por debajo de 30fps al mostrar la tabla de personas
- Hipótesis: PeopleStore.people decodifica JSON en cada acceso a celda
- Instrumento elegido: Time Profiler
- Resultado: Confirmado — JSONDecoder.decode aparece 847 veces en 5 segundos
- Siguiente paso: Cachear el resultado de la decodificación en una propiedad lazy
Anatomía del Time Profiler
Ya usamos Time Profiler en la Parte 1 para diagnosticar el problema de SuperStuff. Pero ¿realmente entendemos cómo funciona? Porque Time Profiler no graba cada nanosegundo de ejecución. Utiliza muestreo (sampling).
Cómo funciona el sampling
Por defecto, Time Profiler dispara un temporizador aproximadamente 1,000 veces por segundo — una muestra cada milisegundo. En cada muestra, captura el stack trace completo de cada hilo activo: qué función se está ejecutando, quién la llamó, quién llamó a esa, y así sucesivamente hasta llegar al main().
Eso significa que Time Profiler es estadístico, no exacto. Una función que se ejecuta durante 0.5 milisegundos entre dos muestras podría no aparecer nunca. Pero esto no es una limitación — es una feature. Las funciones que aparecen en más muestras son las que consumen más tiempo proporcionalmente. Y las proporciones son lo que importa para optimizar.
Weight vs Self-Weight: el gerente y el obrero
Estas dos columnas del Call Tree son la clave para entender dónde está realmente el problema.
Weight es el tiempo total que una función aparece en los stacks muestreados — incluyendo el tiempo de todas las funciones que llama. Si cellForRowAt aparece en 850 muestras, su Weight es 850ms. Pero eso no significa que cellForRowAt sea lenta por sí misma — puede que simplemente sea la “puerta de entrada” a funciones lentas más abajo.
Self-Weight es el tiempo en que esa función específica estaba en la cima del stack — es decir, era la función que realmente se estaba ejecutando en el momento de la muestra. Si cellForRowAt tiene Self-Weight de 5ms, significa que solo 5 de esas 850 muestras capturaron a cellForRowAt haciendo trabajo propio. Las otras 845 muestras la encontraron esperando a que funciones más profundas terminaran.
Weight te dice quién inició el trabajo. Self-Weight te dice quién lo hizo. La diferencia entre ambos es la diferencia entre el gerente y el obrero.
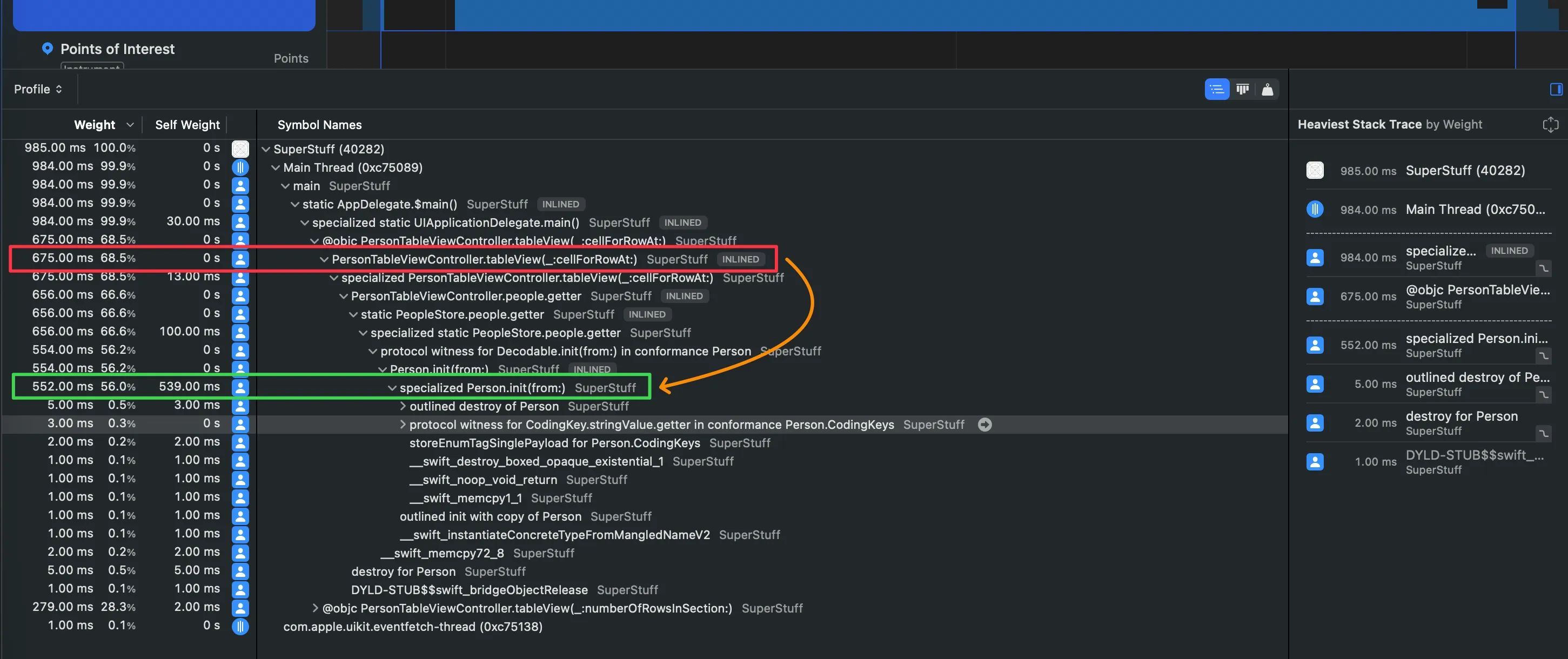
- Weight = tiempo total que la función aparece en cualquier stack muestreado (incluye descendientes)
- Self-Weight = tiempo que la función está en el TOP del stack (trabajo propio)
- Weight alto + Self alto = función hoja haciendo trabajo pesado. Candidata directa a optimización
- Weight alto + Self bajo = coordinador que llama a funciones costosas. Sigue descendiendo
- Weight bajo = no es un contribuidor significativo al problema
Cirugía de datos: Charge, Prune y Flatten
Filtrar con “Hide System Libraries” es un gran primer paso, pero a veces no es suficiente. Tu Call Tree sigue lleno de funciones intermedias, wrappers de frameworks, y protocol witness thunks que añaden ruido sin aportar información. Instruments ofrece tres operaciones de precisión para manipular el árbol de llamadas.
Flatten
¿Qué hace? Elimina una función del árbol y sube sus hijos directamente al padre. Es como quitar un eslabón de una cadena — los eslabones adyacentes se conectan directamente.
¿Cuándo usarlo? Cuando una función intermedia es solo un “puente” que no aporta información. Protocol witness thunks, wrappers genéricos, o funciones con Self-Weight cercano a 0 son candidatas perfectas.
Prune
¿Qué hace? Elimina una función y todos sus descendientes del análisis. El tiempo completo de esa rama desaparece.
¿Cuándo usarlo? Cuando has identificado un subárbol que sabes que es irrelevante para tu investigación. Si estás persiguiendo un problema de CPU y el SDK de analytics aparece con 50ms, puedes podarlo para limpiar el ruido.
Charge
¿Qué hace? Colapsa todos los hijos de una función, absorbiendo su tiempo. El Self-Weight de la función se vuelve igual a su Weight — se convierte en una caja negra.
¿Cuándo usarlo? Cuando ya sabes que una operación es costosa y quieres ver su costo total consolidado para compararlo con otras ramas del árbol.
- Flatten → Elimina la función, sube sus hijos al padre. No pierde tiempo. Para intermediarios ruidosos.
- Prune → Elimina la función Y sus hijos. El tiempo desaparece. Para ramas irrelevantes.
- Charge → Colapsa hijos en la función. Self = Weight. Para ver costo total como caja negra.
- Cómo acceder: Clic derecho sobre cualquier función en el Call Tree de Instruments.
Pero leer sobre estas operaciones no es lo mismo que verlas en acción. Usa el componente interactivo para experimentar con cada una sobre un Call Tree basado en datos reales de SuperStuff:
Cirugía del Call Tree
Experimenta con Flatten, Prune y Charge sobre un Call Tree real de SuperStuff.
Elimina una función intermedia y sube sus hijos al padre.
Del Time Profiler al Processor Trace
No todos los instrumentos de tiempo son iguales. Piensa en ellos como tres niveles de aumento de un microscopio — cada uno revela más detalle, pero a mayor costo.
Nivel 1: Time Profiler (basado en temporizador)
Es lo que hemos usado hasta ahora. Un temporizador dispara ~1,000 veces por segundo y captura el stack trace. Es ligero (~5% de overhead), funciona en cualquier hardware Apple, y es perfecto como punto de partida. La inmensa mayoría de los problemas de rendimiento se pueden diagnosticar aquí.
Su limitación: al ser estadístico, puede perder funciones muy cortas que se ejecutan entre dos muestras.
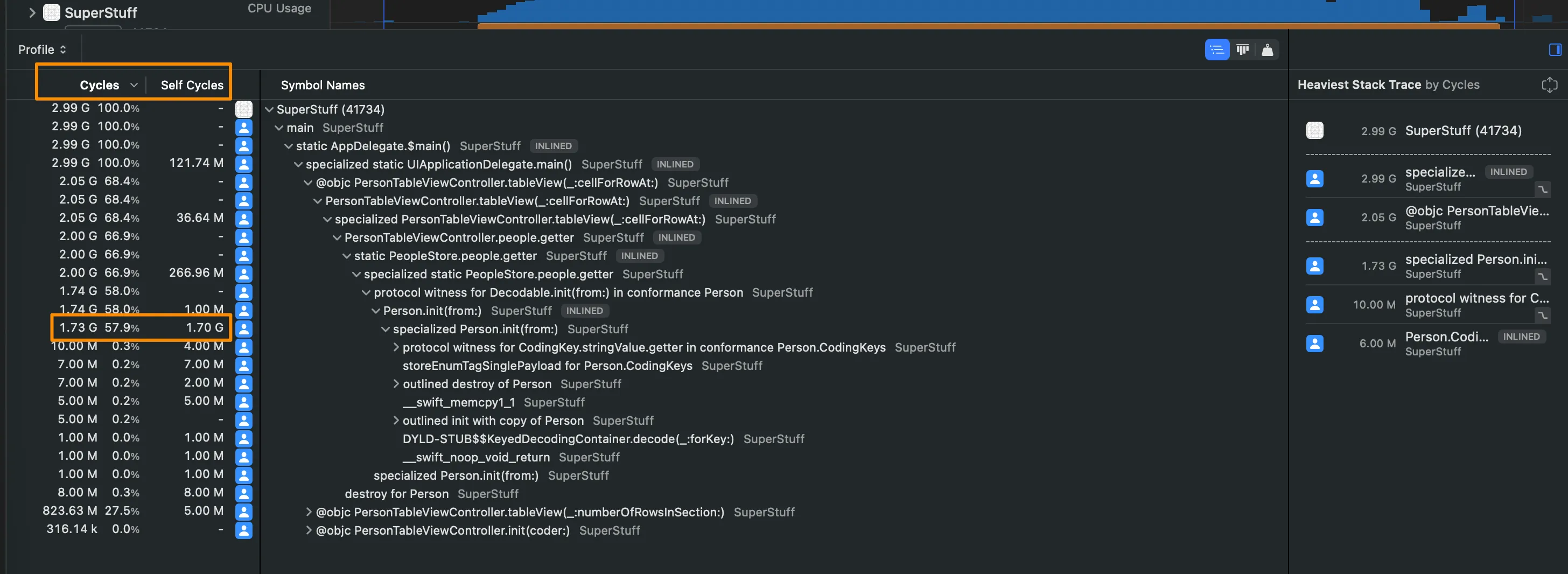
Nivel 2: CPU Profiler (basado en contadores de hardware)
En lugar de un temporizador, el CPU Profiler usa los Performance Monitoring Counters (PMCs) del procesador — contadores de hardware que miden ciclos de reloj reales. Esto significa que las muestras se distribuyen según cuánto trabajo real hace cada núcleo, no según el tiempo de reloj de pared.
En la práctica, esto te da unidades en ciclos en vez de milisegundos, lo que es más fiel al costo real del código en el hardware. Disponible en todo Apple Silicon.
Nivel 3: Processor Trace (grabación de cada instrucción)
El nivel definitivo. Processor Trace no muestrea — graba absolutamente cada instrucción ejecutada por cada núcleo. Nada se escapa. Donde Time Profiler te da 1,400 muestras en un segundo, Processor Trace puede darte 117 millones de registros en el mismo intervalo.
Requiere hardware moderno (M4 o A18 en adelante) y, sorprendentemente, genera un overhead de apenas ~1% según Apple. Sin embargo, produce volúmenes masivos de datos (gigabytes por segundo en apps multi-hilo), por lo que está diseñado para grabaciones cortas y muy dirigidas. Perfecto para responder: “¿esta función se ejecutó o no?” o “¿qué camino exacto tomó la ejecución dentro de este framework?”
Time Profiler te dice dónde tu app gasta su tiempo. CPU Profiler te dice dónde gasta sus ciclos. Processor Trace te dice exactamente qué pasó — cada instrucción, cada salto, cada llamada.
- Time Profiler → Temporizador ~1kHz | ~5% overhead | Estadístico | Todo hardware Apple
- CPU Profiler → Contadores PMC | ~5-10% overhead | Estadístico (por ciclos) | Apple Silicon
- Processor Trace → Cada instrucción | ~1% overhead (pero genera GBs de datos) | Determinístico | Solo M4/A18+
- Recomendación: Empieza siempre con Time Profiler. Escala solo cuando necesites más precisión.
Profiling en CI con xctrace
Todo lo que hemos hecho hasta ahora ha sido interactivo — abres Instruments, grabas manualmente, analizas con los ojos. Pero los problemas de rendimiento no siempre ocurren mientras estás mirando. Necesitas automatizar.
xctrace es la herramienta de línea de comandos que vive detrás de Instruments. Todo lo que puedes hacer en la interfaz gráfica, puedes scriptarlo.
Grabar un trace desde Terminal
# Grabar un trace de Time Profiler de 10 segundosxctrace record --template "Time Profiler" \ --output ./traces/perf_$(date +%Y%m%d).trace \ --time-limit 10s \ --attach "SuperStuff"Exportar datos para análisis automatizado
# Exportar los datos del trace como XMLxctrace export --input ./traces/perf_20260514.trace \ --xpath '/trace-toc/run/data/table[@schema="time-profile"]'Integración con tests de rendimiento
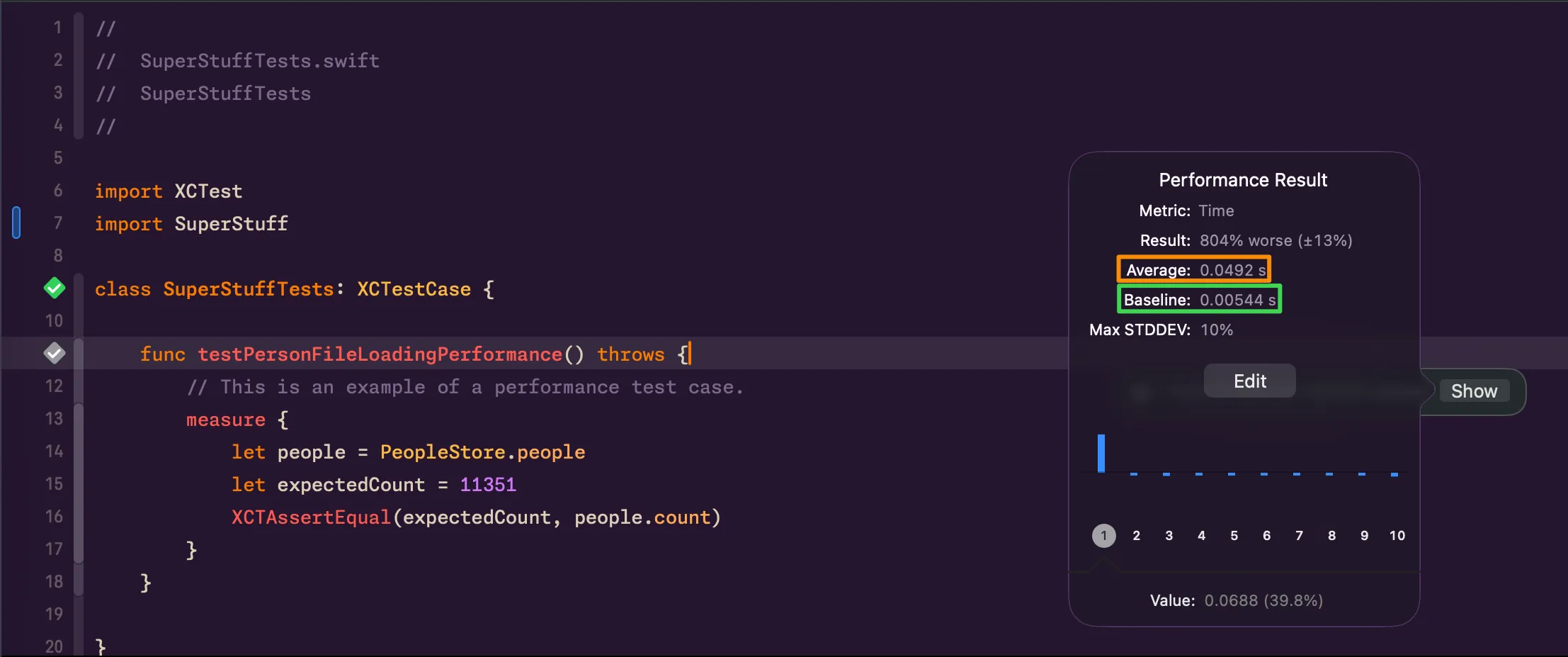
¿Recuerdas el test testPersonFileLoadingPerformance de SuperStuff?
func testPersonFileLoadingPerformance() throws { measure { let people = PeopleStore.people XCTAssertEqual(11351, people.count) }}El bloque measure { } ejecuta el código múltiples veces, calcula la media, y la compara contra un baseline que defines en Xcode. Si la media excede el baseline por un margen configurable, el test falla. En CI, esto se convierte en tu red de seguridad contra regresiones de rendimiento.
xctrace record→ Grabar un nuevo trace (requiere —template y —output)xctrace export→ Exportar datos de un trace existentexctrace list devices→ Listar dispositivos disponiblesxctrace list templates→ Listar plantillas de Instruments disponiblesxctrace list instruments→ Listar instrumentos individuales disponiblesman xctrace→ Documentación completa en tu Terminal
Conectando los puntos
Hoy cubrimos el arco completo: del caos emocional del “algo está lento” al proceso metódico de observar, hipotetizar, medir e interpretar. Aprendimos a leer Weight y Self-Weight como un patólogo lee una biopsia — no solo mirando números, sino entendiendo qué significan sobre la estructura del problema. Dominamos las tres operaciones de cirugía del Call Tree que separan a los principiantes de los expertos. Y vimos cómo escalar nuestro profiling desde el desarrollo local hasta la integración continua.
La escalera es clara: empieza siempre con Time Profiler. Es la herramienta más balanceada, la que aparece en la mayoría de las plantillas, y la que resuelve el 90% de los problemas. Solo cuando identifiques una sección que necesite micro-optimización o quieras hacer “arqueología” dentro de un framework cerrado, escala al CPU Profiler o al Processor Trace.
Si no puedes medir el rendimiento automáticamente, no puedes protegerlo automáticamente. Y si no puedes protegerlo, cada deploy es un acto de fe.
Hasta ahora nos hemos enfocado en CPU — dónde se gasta el tiempo de procesamiento. Pero hay otra mitad de la ecuación que puede degradar tu app silenciosamente: la memoria. Retain cycles que nunca se liberan, allocations descontroladas, objetos zombie que crashean tu app días después de ser liberados.
Referencias
- Analyzing CPU Usage with the Time Profiler — Apple Documentation — Documentación oficial de Apple sobre el instrumento Time Profiler.
- Getting Started with Instruments — WWDC19 — Sesión de Apple que cubre los fundamentos de Instruments, incluyendo manipulación del Call Tree.
- Improving App Responsiveness — Apple Documentation — Guía de Apple sobre hangs, hitches y mejores prácticas para mantener el hilo principal libre.
- xctrace — Apple Developer Man Pages — Referencia completa de la herramienta de línea de comandos xctrace.
- Hacking with Swift: How to use Instruments — Paul Hudson — Guía práctica de Paul Hudson sobre optimización con Instruments.
- Xcode Instruments Time Profiler — Antoine van der Lee — Tutorial de Antoine van der Lee sobre el uso efectivo del Time Profiler.
Relacionados
-
- swift
- swift-cero-experto
- swift-fundamentals
Swift de Cero a Experto #11: Opcionales y Optional Chaining
El antídoto de Swift al error de mil millones de dólares. Optional es solo un enum — y nil, if let, guard let, ??, ! y el optional chaining compilan a preguntar en qué case estás.
-
- swift
- swift-cero-experto
- swift-fundamentals
Swift de Cero a Experto #10: Herencia e Inicialización
Subclassing, overriding y super. Designated vs convenience initializers, two-phase initialization, failable y required init, y deinit — el ciclo de vida completo de una class, explicado en memoria.
-
- swift
- swift-cero-experto
- swift-fundamentals
Swift de Cero a Experto #9: Propiedades, métodos y subscripts
Stored vs computed properties, observers, lazy, static. Cómo las propiedades definen el layout en memoria y por qué computed = zero storage.